
DataComp Workshop
Oral Presenters
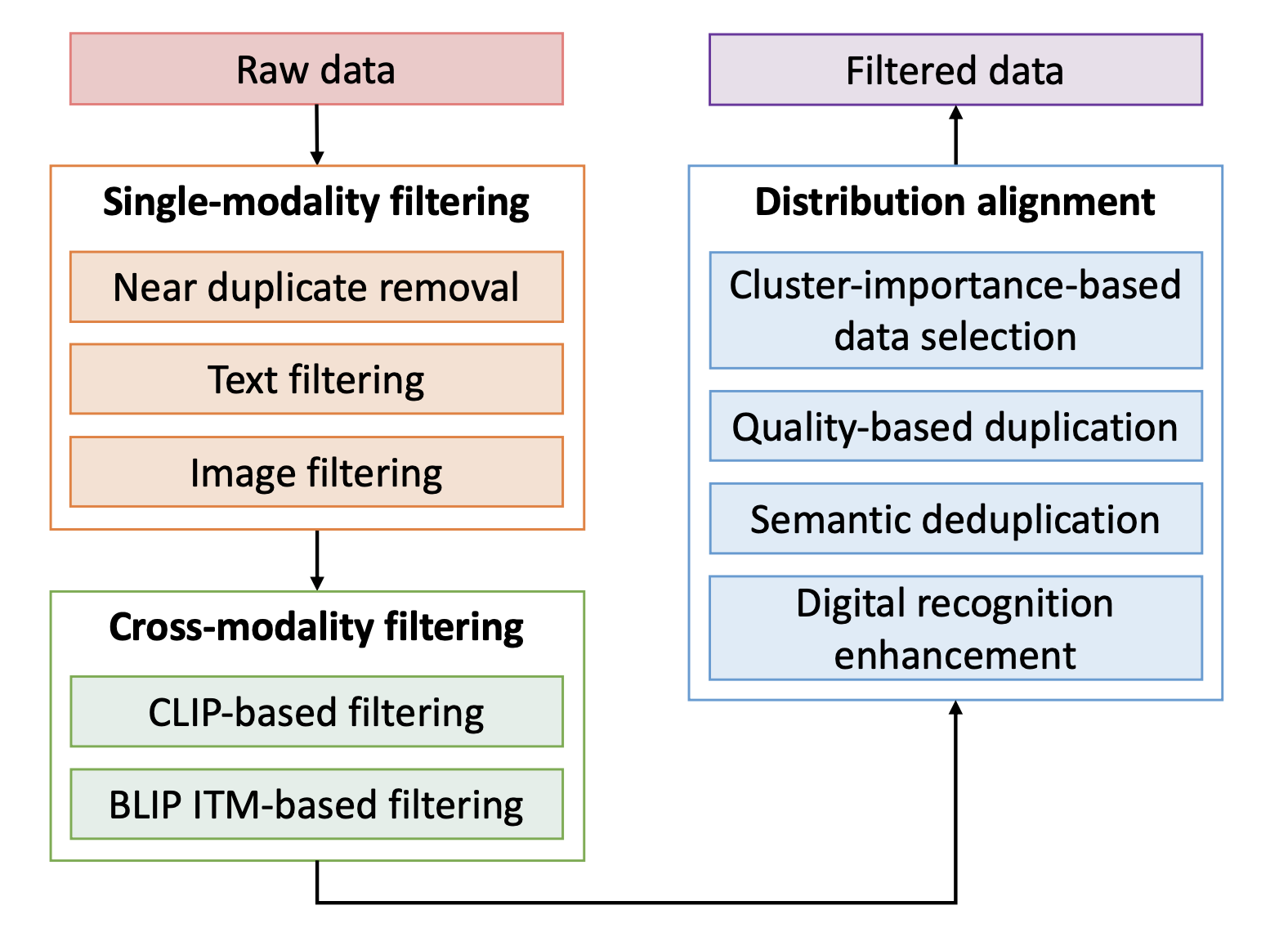
The Devil is in the Details: A Deep Dive into the Rabbit Hole of Data Filtering
Haichao Yu, Yu Tian, Sateesh Kumar, Linjie Yang, Heng Wang
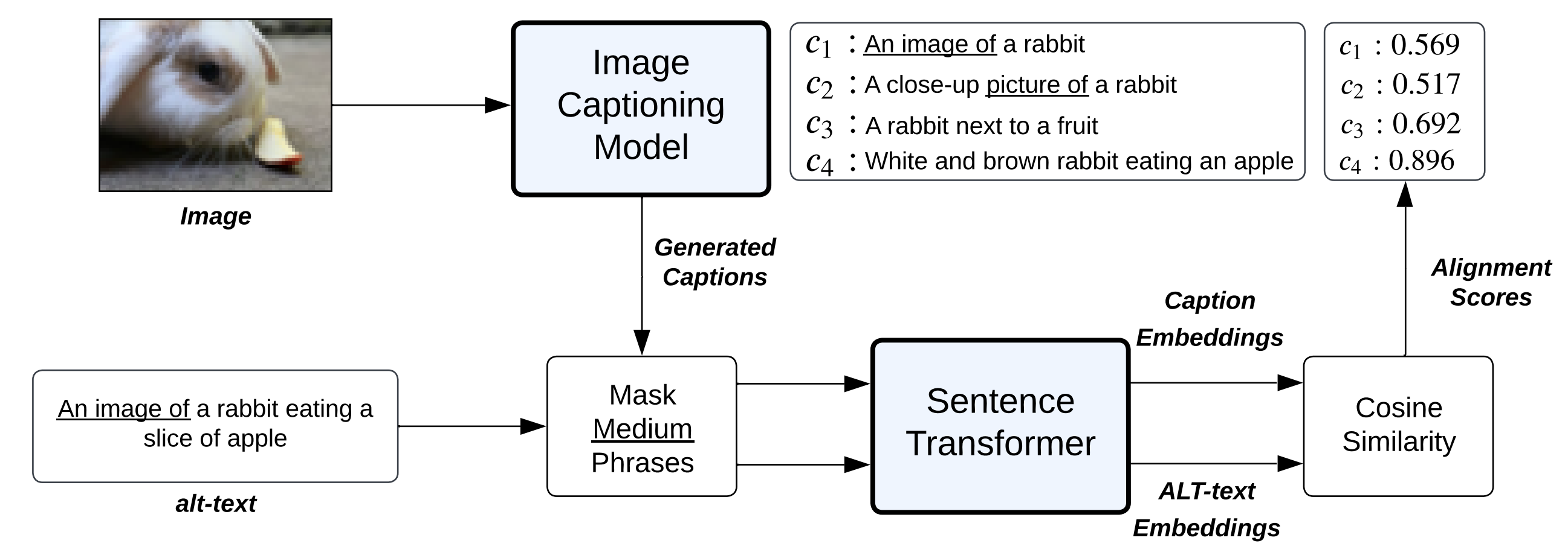
SIEVE: Multimodal Dataset Pruning using Image-Captioning Models
Anas Mahmoud, Mostafa Elhoushi, Amro Abbas, Yu Yang, Newsha Ardalani, Hugh Leather, Ari Morcos
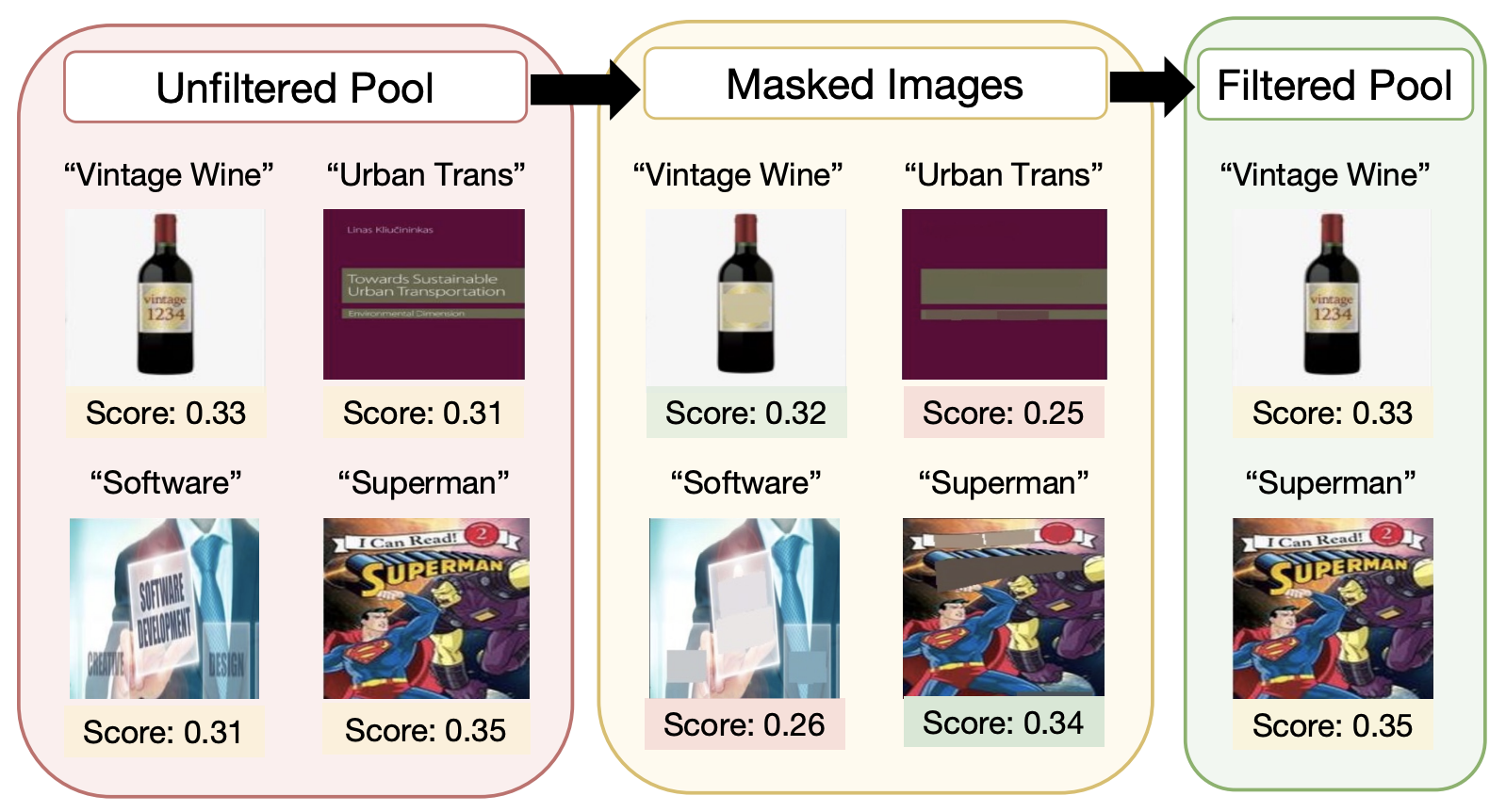
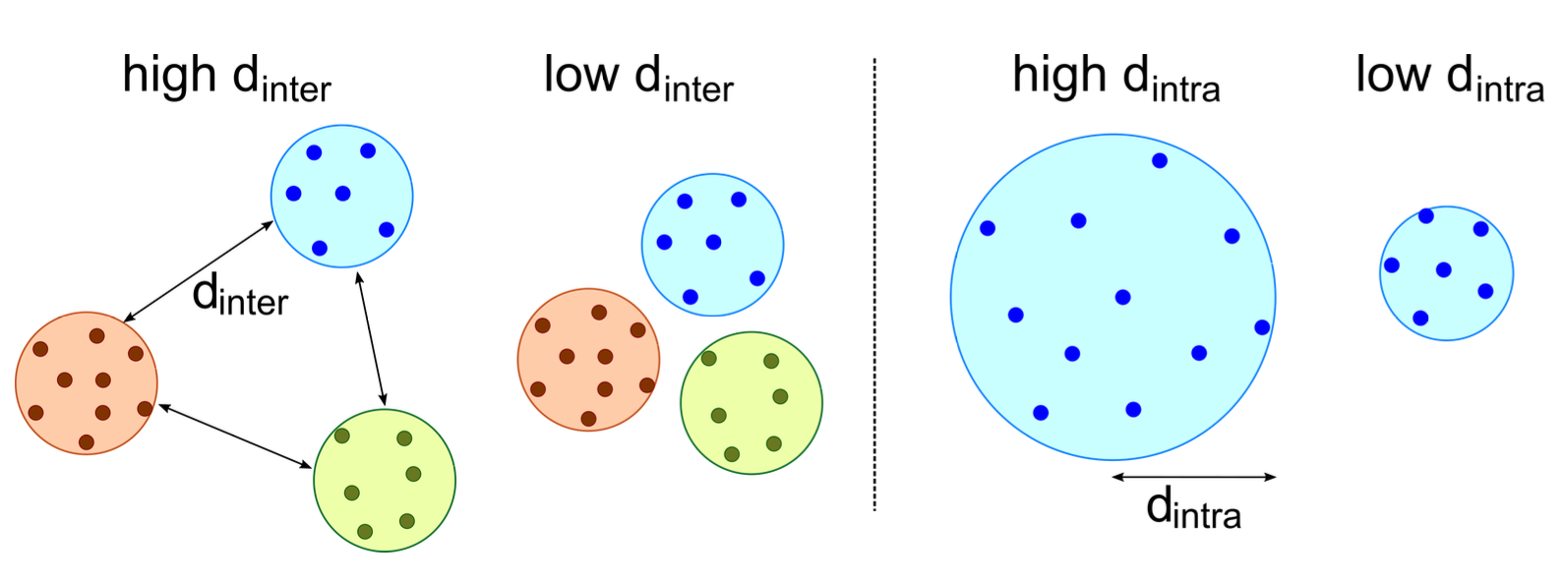
Concept-based data-driven curation of large-scale datasets
Amro Abbas, Evgenia Rusak, Wieland Brendel, Kamalika Chaudhuri, Ari Morcos
Winners as of Workshop

Filtering Track
Small: SprocketLab
Medium: The Devil Is in the Details [PDF]
Large: SIEVE [ARXIV]
XLarge: Baseline: Image-based ∩ CLIP score (L/14 30%) [ARXIV]
BYOD Track
Small: BLIP caption modification (50%) + CC12M (30%) + Eval_trainsets (MNIST*3)
Medium: Image-cluster and CLIP (40%) + CC12M (50%) + Eval_trainsets (MNIST*3)
Large: Improving Multimodal Datasets with Image Captioning [ARXIV]
XLarge: Baseline: CommonPool CLIP score filter + 4 external sources (upsampled 6x) [ARXIV]
October 3, 2023 - ICCV, Paris
Our workshop Towards the Next Generation of Computer Vision Datasets is taking place at ICCV 2023 in Paris.
The workshop will be held in Room E03
The workshop will showcase a series of DataComp submissions, along with other data-centric papers and multiple invited talks by experts in the field.
You can join remotely here
Workshop Schedule
The workshop will take place on October 3, 2023. The schedule is as follows:
- 9:00 AM - Opening Remarks
- 9:30 AM - Invited Talk - Olga Russakovsky
- 10:00 AM - Coffee Break
- 10:30 AM - Contributed Oral Presentations/Poster Session
- 12:00 PM - Lunch Break
- 1:30 PM - Invited Talk - Georgia Gkioxari
- 2:00 PM - Invited Talk - Dragomir Anguelov: The Waymo Open Dataset and Challenges
- 2:30 PM - Contributed Oral Presentations/Poster Session
- 3:30 PM - Invited Talk - Joao Carreira: From Kinetics to Perception Test and Beyond
- 4:00 PM - Invited Talk - Tom Duerig: Vision Datasets (past and future)
- 4:30 PM - Invited Talk - Swabha Swayamdipta: Understanding Data with 𝒱 -Information
- 5:00 PM - Panel Discussion and Closing Remarks
Speakers

Assistant Professor
Caltech

Research Scientist
Waymo

Assistant Professor
Princeton

Research Scientist
DeepMind

Engineer and Manager
Google Research

Assistant Professor
USC
Workshop Organizers

Samir Gadre
Columbia
University

Gabriel Ilharco
University of
Washington

Alex Fang
Apple

Thao Nguyen
University of
Washington

Mitchell Wortsman
University of
Washington

Achal Dave
Toyota Research
Institute

Ari Morcos
Meta AI Research

Jon Shlens
Google
DeepMind

Sarah Pratt
University of
Washington

Ali Farhadi
University of
Washington

Yair Carmon
Tel Aviv
University

Vaishaal Shankar
Apple

Ludwig Schmidt
University of
Washington & AI2 & LAION
Why work on Datasets?
Despite the central role large image-text datasets play in multimodal learning, little is known about them. Many state-of-the-art datasets are proprietary and only available in corporate research labs, as in the case of CLIP, DALL-E, Flamingo, and GPT-4. But even for public datasets such as LAION-2B. it is unclear how design choices during dataset construction, such as the data source or filtering techniques, affect the resulting models. While there are thousands of ablation studies for algorithmic design choices (loss function, optimizer, model architecture, etc.), datasets are usually treated as monolithic artifacts without detailed investigation or further improvements. Moreover, datasets currently lack the benchmark-driven development process that has enabled the community to produce a steady stream of advances on the model side. The hope is that we can use this workshop and the DataComp benchmark as a way to drive community involvement in this space.
Call for DataComp Submission Papers
We invite researchers and practitioners to submit a short paper detailing their DataComp Submissions (for any track!) to the workshop. The top performing submissions will be invited to give a talk during the workshop. All accepted submissions will be given a chance to present a poster. Submitted papers should not exceed 4 pages (excluding references) and should follow the ICCV 2023 formatting guidelines. The submission deadline will be September 8th, 2023 AOE. Accepted papers will be presented at the workshop. The submission portal for workshop papers is here
Call for Other Data-Centric Papers
We also invite researchers and practitioners to submit papers related to the next generation of computer vision datasets. Topics of interest include but are not limited to:
- Novel data collection, curation, and annotation methodologies
- Dataset bias, fairness, and ethical considerations
- Dataset quality assessment and improvement
- Active learning and dataset curation
- Domain adaptation and transfer learning
Submitted papers should not exceed 4 pages (excluding references) and should follow the ICCV 2023 formatting guidelines. The submission deadline will be September 8th, 2023 AOE. Accepted papers will be presented at the workshop. The submission portal for workshop papers is here
Getting started with DataComp
You can find instructions to get started with DataComp at our github repository
You can get started by downloading our smallest (12.8M) data pool to your current directory with the following commands (note this pool is 450GB so the download can take a few hours)
git clone https://github.com/mlfoundations/datacomp.git
cd datacomp
bash create_env.sh
conda activate datacomp
python download_upstream.py --scale small --data_dir .